§ Обработка результатов тестирования
Рассмотрим самые простые и необходимые процедуры статистической
обработки результатов тестирования знаний и методы оценки качества теста в
соответствии с классической теорией тестирования.
Обозначим через xij числовую оценку
успешности выполнения j-го задания, выполненного i-м испытуемым.
Результаты тестирования обычно представляются в виде матрицы
{xij} с n строками и m столбцами (i=1,…,n;
j=1,…,m). В практике тестирования принято, как правило, пользоваться
дихотомической шкалой оценок результатов, когда множество возможных оценок
состоит всего из двух элементов {0;1}: 0 – задание не выполнено, 1 – выполнено
правильно. Это, конечно, не единственно возможная шкала. Расчет, однако, ведется
по формулам, приведенным ниже, независимо от выбранной для оценок шкалы.
Процесс статистической обработки матрицы результатов
тестирования будем рассматривать последовательно, по шагам.
- 1 шаг. Вычисляются индивидуальные баллы испытуемых yi (i=1,…,n), показывающие результат выполнения теста
каждым студентом:
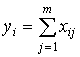 . .
Поскольку для проверки статистических гипотез, которые
применяются в классической теории тестов, используют предположение о нормальном
распределении суммарных баллов испытуемых, то рекомендуется исследовать
распределение частот. Для сравнения распределения баллов с нормальным можно
использовать любой из критериев, применяемых обычно для этой цели.
- 2 шаг. Вычисляются средние результаты
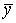 суммарных баллов испытуемых: суммарных баллов испытуемых:
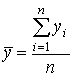 . .
- 3 шаг. Вычисляются средние результаты
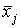 испытуемых по каждому заданию: испытуемых по каждому заданию:
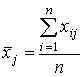 .
Для дихотомических данных величины, вычисляемые по
аналогичной формуле, обозначаются через pj и традиционно
называются в тестологии мерой трудности задания j (j=1,2,…,m): .
Для дихотомических данных величины, вычисляемые по
аналогичной формуле, обозначаются через pj и традиционно
называются в тестологии мерой трудности задания j (j=1,2,…,m):
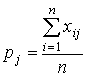 .
Заметим, однако, что чем больше величина
коэффициента pj, тем большая часть испытуемых успешно
справляется с заданием j. Так что на самом деле коэффициенты pj (j=1,2,...,m) должны интерпретироваться как показатели
легкости заданий. .
Заметим, однако, что чем больше величина
коэффициента pj, тем большая часть испытуемых успешно
справляется с заданием j. Так что на самом деле коэффициенты pj (j=1,2,...,m) должны интерпретироваться как показатели
легкости заданий.
- 4 шаг. Вычисляется дисперсия
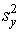 и стандартное отклонение и стандартное отклонение 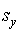 суммарных баллов испытуемых: суммарных баллов испытуемых:
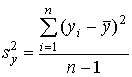 , , 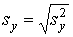 . .
- 5 шаг. Вычисляется дисперсия
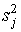 результатов испытуемых по j–ому заданию (j=1,…,m). Если успешность выполнения задания оценивается баллами 0 или 1, мера
вариации определяется по формуле: результатов испытуемых по j–ому заданию (j=1,…,m). Если успешность выполнения задания оценивается баллами 0 или 1, мера
вариации определяется по формуле:
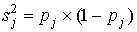 .
Когда множество оценок состоит из более чем двух
значений, применима формула: .
Когда множество оценок состоит из более чем двух
значений, применима формула:
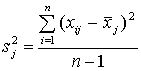 .
Вычислив дисперсию, можно найти и стандартное
отклонение .
Вычислив дисперсию, можно найти и стандартное
отклонение 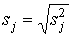 . .
- 6 шаг. Определяется связь каждого j–го задания
(j=1,…,m) с суммой баллов по всему тесту. Для этого можно использовать
коэффициент корреляции Пирсона:
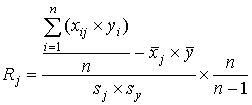 . .
- 7 шаг.Определяется попарная корреляционная связь заданий между собой.
Здесь тоже можно использовать коэффициент корреляции Пирсона rjk, (j,k=1, 2,…,m):
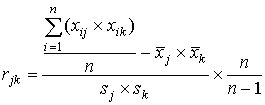 .
Для дихотомических оценок успешности выполнения
заданий тот же результат можно получить, оценив эту связь посредством
коэффициента корреляции .
Для дихотомических оценок успешности выполнения
заданий тот же результат можно получить, оценив эту связь посредством
коэффициента корреляции 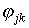 (j,k=1, 2,…,m) для такого рода данных: (j,k=1, 2,…,m) для такого рода данных:
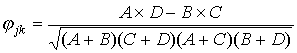 ,
где A– количество испытуемых, верно
выполнивших задания jи k; B, - количество испытуемых, верно
выполнивших задание jи неверно - задание k; C - количество
испытуемых, неверно выполнивших задание j и верно задание k; D - количество испытуемых, неверно выполнивших задания jи k.Очевидно, величины A,B,C и D вычисляются по формулам: ,
где A– количество испытуемых, верно
выполнивших задания jи k; B, - количество испытуемых, верно
выполнивших задание jи неверно - задание k; C - количество
испытуемых, неверно выполнивших задание j и верно задание k; D - количество испытуемых, неверно выполнивших задания jи k.Очевидно, величины A,B,C и D вычисляются по формулам:
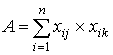 , , 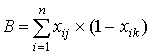 , ,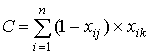 , ,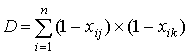 . .
- 8 шаг. Вычисляется индекс Ij(j=1, 2, …
m)дискриминативности задания, то есть его различающая способность,
указывающая на возможность разделять отдельных испытуемых по уровню выполнения
теста в целом. Для этого из общей совокупности испытуемых выделяют две подгруппы
– тех, кто получил самые высокие суммарные баллы, и тех, кто получил самые
низкие. Тогда индекс дискриминативности может быть определен как разность между
относительными численностями испытуемых, правильно выполнивших задание jв
этих двух подгруппах. Например, упорядоченную совокупность суммарных баллов
делят на три части и сравнивают результаты выполнения каждого задания j первой и последней третями испытуемых.В этом случае для дихотомических данных
индекс приобретает вид:
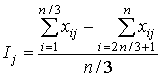
Чем больше коэффициент Ij, тем больше
дискриминативность задания.
При наличии больших выборочных совокупностей
дихотомических данных и нормального распределения индивидуальных сумм баллов
рекомендуют рассчитывать для всех заданий бисериальные коэффициенты корреляции Вj (j=1, 2, … m):
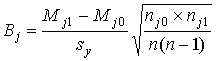 где Mj1– среднее арифметическое сумм
баллов по всему тесту для испытуемых, получивших по данному заданию 1 балл; Mj0– среднее арифметическое сумм баллов по всему тесту для
испытуемых, получивших по данному заданию 0 баллов; nj1– число
испытуемых, получивших по данному заданию 1 балл; nj0– число
испытуемых, получивших по данному заданию 0 баллов.Очевидно, входящие в формулу
величины могут быть рассчитаны следующим образом:
где Mj1– среднее арифметическое сумм
баллов по всему тесту для испытуемых, получивших по данному заданию 1 балл; Mj0– среднее арифметическое сумм баллов по всему тесту для
испытуемых, получивших по данному заданию 0 баллов; nj1– число
испытуемых, получивших по данному заданию 1 балл; nj0– число
испытуемых, получивших по данному заданию 0 баллов.Очевидно, входящие в формулу
величины могут быть рассчитаны следующим образом:
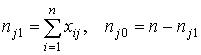 , ,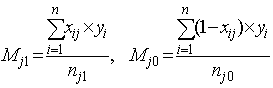
- 9 шаг.Очередной шаг делается на основе вектора корреляций
{Rj} (или {Вj}), корреляционной матрицы
 } (или { } (или {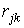 }) и вектора коэффициентов трудности
{pj}. Из собрания тестовых заданий удаляются задания, не
обладающие дискриминативностью, то есть задания слишком легкие
(pj>0,9) и слишком трудные (pj <0,2). Затем исключаются задания, плохо коррелирующие с
суммой баллов (Rj<0,15), и имеющие отрицательные
коэффициенты корреляции }) и вектора коэффициентов трудности
{pj}. Из собрания тестовых заданий удаляются задания, не
обладающие дискриминативностью, то есть задания слишком легкие
(pj>0,9) и слишком трудные (pj <0,2). Затем исключаются задания, плохо коррелирующие с
суммой баллов (Rj<0,15), и имеющие отрицательные
коэффициенты корреляции 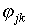 (или rjk). (или rjk).
- 10 шаг. Для укороченного списка заданий вновь подсчитываются
суммарные баллы испытуемых yi. Затем составляется новая,
упорядоченная, матрица данных тестирования, в которой столбцы располагаются в
порядке возрастания трудности заданий, а строки – в порядке уменьшения, сверху
вниз, суммарных баллов испытуемых. Для редуцированной матрицы пересчитываются
средний суммарный балл, дисперсия суммарных баллов и коэффициенты корреляции
заданий с суммой баллов.
Проверка качества
теста
Чтобы полученное собрание тестовых заданий можно было считать
тестом, оно должно удовлетворять определенным критериям надежности и
валидности.
Надежность теста r тем выше, чем более согласованы результаты одного и того же человека при
повторной проверке знаний посредством того же теста или эквивалентной его формы
(параллельного теста). Согласованность результатов можно измерять коэффициентом
корреляции Пирсона.
Если значения коэффициента r
попадают в интервал 0,80-0,89, то
говорят, что тест обладает хорошей надежностью, а если этот коэффициент не
меньше 0,90, то надежность можно назвать очень высокой.
Другие, более практичные, методы оценки надежности теста,
основаны на однократном применении единственной формы теста.
При применении метода расщепления откорректированную выше
описанным образом тестовую матрицу разбивают на две половины, состоящие из
заданий с четными и нечетными номерами. Коэффициент корреляции r1/2 Пирсона между двумя совокупностями суммарных баллов результатов сам по
себе уже может служить оценкой надежности всего теста.
Оценку надежности полного теста можно делать также с
использованием коэффициента корреляции r1/2, по формуле
Спирмана-Брауна :
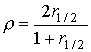 .
Другой способ оценки надежности расщепленного теста
основан на формуле Рюлона: .
Другой способ оценки надежности расщепленного теста
основан на формуле Рюлона:
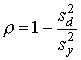 , ,
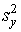 - дисперсия суммарных баллов результата,а - дисперсия суммарных баллов результата,а 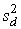 - дисперсия разностей между результатами каждого испытуемого по
обеим половинам теста. Она вычисляется по формуле : - дисперсия разностей между результатами каждого испытуемого по
обеим половинам теста. Она вычисляется по формуле :
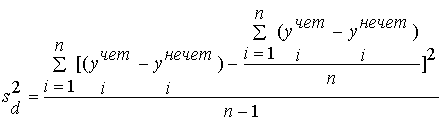
Здесь ( yiчет-yiнечет),
(i=1,2,…n) - разность сумм баллов в строках с номером i субматриц с четными и нечетными заданиями.
Еще один метод определения надежности, основанный на
однократном предъявлении единственной формы теста, носит имя Кьюдера-Ричардсона.
Он использует данные о выполнении испытуемыми каждого задания. Коэффициент
надежности Кьюдера-Ричардсона вычисляется по следующей формуле:
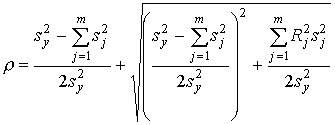
Показано, что такой коэффициент равен среднему арифметическому
значений коэффициентов надежности, найденных по методу расщепления при всех
возможных разбиениях теста.
Чем выше показатель надежности, тем меньше стандартная ошибка
измерения индивидуального результата. Показатель надежности можно использовать
для построения доверительного интервала, в пределах которого с выбранной
вероятностью Р находится истинное значение оценки знаний испытуемого: 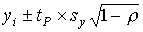 , где tP – значение статистики
Стьюдента, найденное для выбранной вероятности P, когда число испытуемых
равно n. , где tP – значение статистики
Стьюдента, найденное для выбранной вероятности P, когда число испытуемых
равно n.
Валидность теста показывает, насколько хорошо тест
делает то, для чего он был создан. Определить коэффициент валидности теста –
значит определить, как выполнение теста соотносится с другими независимо
сделанными оценками знаний испытуемых. Для определения валидности требуется
независимый внешний критерий, то есть оценка эксперта (преподавателя). За
коэффициент валидности принимают коэффициент корреляции результатов тестовых
измерений и критерия. Если экспертная оценка знаний испытуемых, полученная
независимо от процедуры тестирования, представлена числовой последовательностью Y1,Y2, …, Yn, то коэффициент валидности
теста может быть рассчитан по формуле:
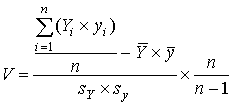 ,
где ,
где 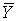 - средняя арифметическая экспертных оценок, sY - стандартное отклонение этих оценок: - средняя арифметическая экспертных оценок, sY - стандартное отклонение этих оценок:
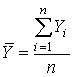 , , 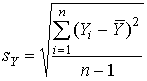 . .
Из двух тестов, предназначенных для одной и той же цели, более эффективен тот, который быстрее, дешевле и качественнее измеряет знания
данной группы испытуемых.
|
|